******************************************* ***COMSOL 5.4.0.225 progress output file*** ******************************************* Thu Feb 20 21:36:07 CST 2020 <---- Compile Equations: Wavelength Domain {st1} in Study 1 {std1}/Solution 1 (sol1) {sol1} ------------------------------------------------------------ Started at Feb 20, 2020 9:36:13 PM. Running on 4 x Intel(R) Xeon(R) Platinum 8163 CPU at 2.50 GHz. Using 4 sockets with 25 cores in total on 4CPU.
运算完毕之后,会有这样的字样
1 2 3 4 5 6 7 8 9
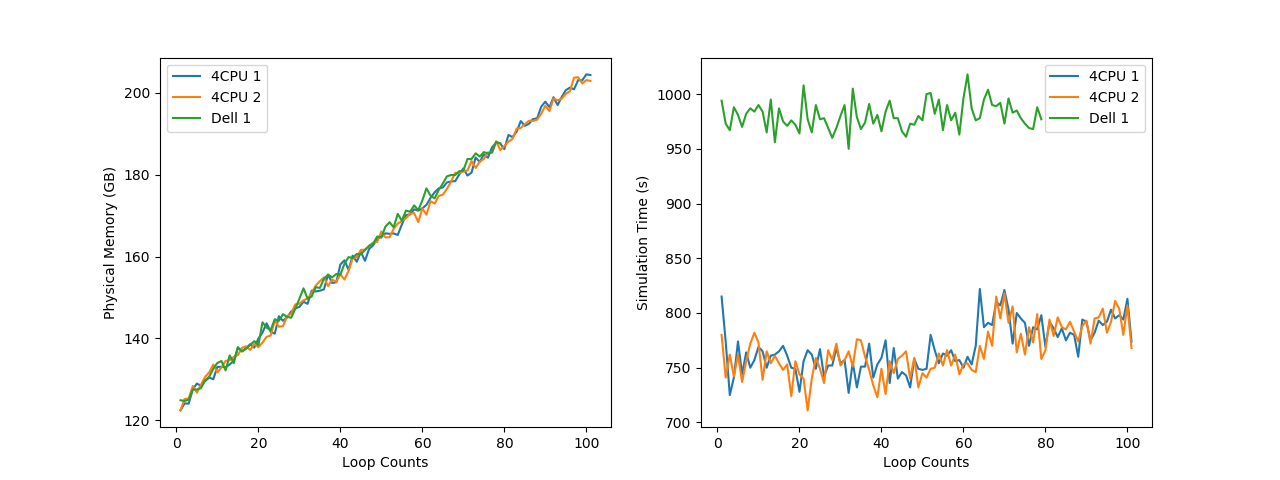
Memory: 106911/106911 151517/151517 Iter SolEst Damping Stepsize #Res #Jac #Sol LinErr LinRes ---------- Current Progress: 100 % - Solving linear system Memory: 115456/117206 149829/151541 1 0.79 1.0000000 0.79 1 1 1 2.2e-11 6.9e-12 Solution time: 815 s. (13 minutes, 35 seconds) Physical memory: 122.42 GB Virtual memory: 156.74 GB Ended at Feb 20, 2020 9:50:10 PM.